Softmax가 만든 병목, FlashAttention는 이를 어떻게 풀었나

- 한눈에 보는 핵심요약
- - Softmax 안의 지수 함수가 왜 GPU에서 병목이 되는지 정리했습니다. - FlashAttention이 메모리 이동이라는 병목을 어떻게 풀었는지 살펴봅니다. - FlashAttention-4와 함께 최근 추론
안녕하세요, 에디터 쏘입니다 :)
LLM 추론 비용은 학습보다 더 큰 문제가 되고 있습니다. 학습은 한 번이지만, 추론은 사용자가 질문할 때마다 반복되기 때문입니다. 주요 LLM API 가격이 2년 사이 80% 넘게 떨어졌지만, 그 이면에는 추론 효율을 극한까지 끌어올려 운영 비용을 낮추려는 치열한 최적화 노력이 있었습니다.
그 핵심 축 중 하나가 FlashAttention입니다. 현재 거의 모든 LLM의 학습과 추론에 사용되고 있는 기법인데요, 지난 3월, Tri Dao 연구팀이 최신 Blackwell GPU에 맞춘 FlashAttention-4을 공개했습니다.
FlashAttention 시리즈는 Transformer의 Attention 연산을 빠르게 만드는 기법으로, 현재 거의 모든 LLM 학습과 추론에 사용되고 있습니다. 그런데 FlashAttention이 정확히 무엇을 최적화하는 건지 이해하려면, 먼저 Attention 연산의 핵심에 있는 Softmax 함수가 왜 병목이 되는지 알아야 합니다.
이번 뉴스레터에서는 Softmax의 역할과 계산 비용을 짚어본 뒤, FlashAttention이 이 문제를 어떻게 풀어왔는지 살펴봅니다. 그리고 FlashAttention 외에도 Sparse Attention, KV Cache 압축, Speculative Decoding 등 추론 최적화의 다양한 흐름을 함께 짚어보겠습니다.
Softmax, 단순한 함수가 아니다
Transformer의 Attention은 간단히 말해 "입력 토큰들 중 지금 어디에 집중할 것인가"를 결정하는 메커니즘입니다. Query(Q)와 Key(K)의 행렬곱으로 각 토큰 쌍의 Attention Score를 구하고, 이 점수에 Softmax를 적용해 확률 분포로 바꾼 뒤, Value(V)를 곱해 최종 출력을 만듭니다. 바로 다음처럼 말이죠.
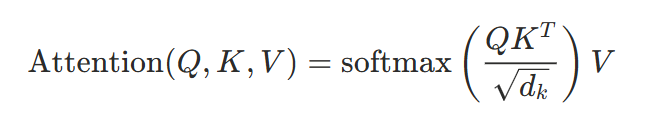
Softmax는 임의의 실수 벡터를 0~1 사이의 확률 분포로 변환하는 함수입니다. 모든 출력값의 합이 1이 되므로, 각 토큰에 대한 집중도를 비율로 해석할 수 있습니다.
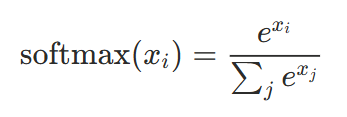
Softmax의 특징은 내부에 지수 함수, exp(x)가 들어간다는 점입니다. 지수 함수는 입력값의 차이를 증폭시킵니다. 예를 들어 Attention Score가 [2.0, 1.0, 0.5]라면, 단순 정규화를 하면 [0.57, 0.29, 0.14]이지만, Softmax를 적용하면 [0.64, 0.24, 0.12]로 큰 값 쪽에 더 집중됩니다. 이 증폭 효과 덕분에 모델은 관련 있는 토큰에 높은 가중치를, 관련 없는 토큰에 낮은 가중치를 부여할 수 있습니다.
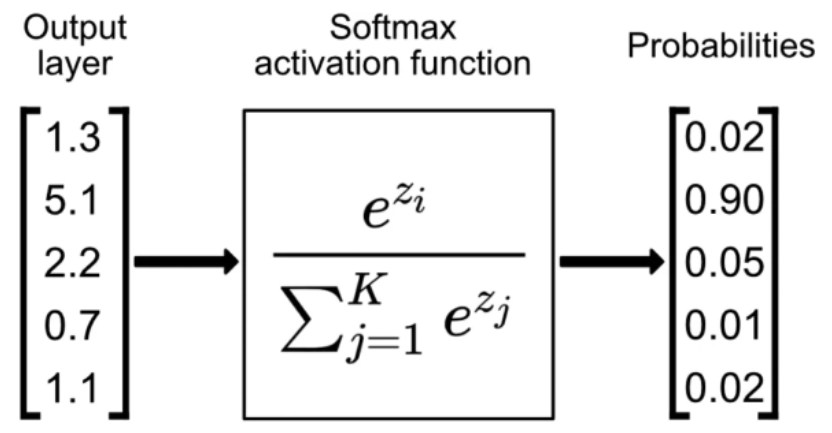
Softmax 계산 출처: SingleStore, <Understanding the Softmax Activation Function: A Comprehensive Guide>
이처럼 Softmax는 표현력 측면에서 중요한 역할을 합니다. Softmax를 제거하고 선형 함수로 대체하려는 Linear Attention과 같은 연구도 오랫동안 연구되고 있으나 쉽게 대체되기 어렵습니다. 그렇다면 Softmax를 유지하면서 효율적으로 계산하는 방법이 필요한데, 이는 수치적으로는 까다로운 함수이기도 합니다.
수치 안정성이라는 숨은 비용
Softmax 함수에서 문제는 지수 함수 exp(x)입니다. x가 조금만 커져도 exp(x)는 폭발적으로 커집니다. 그럼 컴퓨터의 부동소수점 표현을 넘어 Overflow가 발생합니다.
Overflow란 숫자가 컴퓨터가 표현할 수 있는 범위를 넘어 무한대(∞)로 처리되는 현상인데요, LLM에서 많이 쓰이는 FP16 데이터 타입에서는 x가 약 11만 넘어도 Overflow가 발생합니다. Attention Score의 값이 커지면 이 범위를 쉽게 넘을 수 있기 때문에, 그대로 exp(x)를 적용하면 계산이 안되겠죠.
지수함수
그래서 실제 구현에서는 다음처럼 최댓값을 빼주는 트릭을 적용합니다. exp을 적용하기 전 Attention Score 중 최댓값을 빼준 숫자를 exp을 취해주는 것입니다. 다음처럼 말이죠.
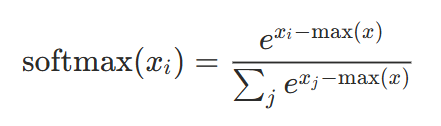
이렇게 최댓값을 빼면 지수 함수의 입력값이 모두 0 이하가 되어 exp 결과는 0~1 사이의 값이 됩니다. 이렇게 Overflow를 방지할 수 있는 거죠. 그리고 최댓값 c를 빼서 계산한 softmax 값과, 빼기 전의 softmax 값은 동일합니다.
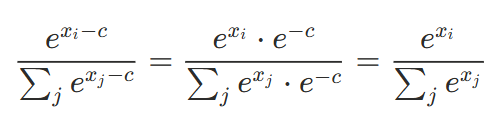
문제는 Softmax를 안정적으로 계산하기 위해 최댓값을 먼저 구하는 과정이 필요하다는 점입니다. 이를 위해 Attention Score 전체를 한 번 순회해야 하고, 이후 exp와 정규화를 위해 다시 접근해야 합니다. 즉, 같은 데이터를 여러 번 읽고 쓰는 과정이 반복됩니다.
FlashAttention: 메모리 이동을 줄이자
2022년, Tri Dao 연구팀은 이 문제에 주목하여 FlashAttention을 발표했습니다. 핵심은 이렇습니다. Attention 연산에서 진짜 느린 건 계산 자체가 아니라, 데이터를 옮기는 시간이라는 것입니다.
GPU에는 두 종류의 메모리가 있습니다. **HBM(High Bandwidth Memory)**은 용량이 크지만(수십 GB) 상대적으로 느리고, SRAM은 빠르지만 용량이 매우 작습니다(약 20MB). GPU의 연산 유닛은 SRAM에 있는 데이터만 직접 처리할 수 있으므로, 모든 연산은 HBM → SRAM으로 데이터를 올리고, 연산한 뒤, 결과를 SRAM → HBM으로 내려보내는 과정을 거칩니다.
기존 Attention 구현에서는 이 왕복이 세 번 발생합니다.
- Q와 K를 HBM → SRAM으로 올려서 행렬곱(QKᵀ)을 수행하고, 결과를 HBM으로 내려보냅니다.
- 그 결과를 다시 HBM → SRAM으로 올려서 Softmax를 계산하고, 결과를 HBM으로 내려보냅니다.
- Softmax 결과와 V를 다시 HBM → SRAM으로 올려서 행렬곱을 수행하고, 최종 결과를 HBM으로 내려보냅니다.
앞서 본 것처럼 Softmax 자체도 최댓값 순회와 정규화를 위해 추가 왕복이 필요합니다. 연산 자체는 빠르지만, 매번 데이터를 옮기는 시간이 쌓여서 전체 속도가 느려지는 것입니다.
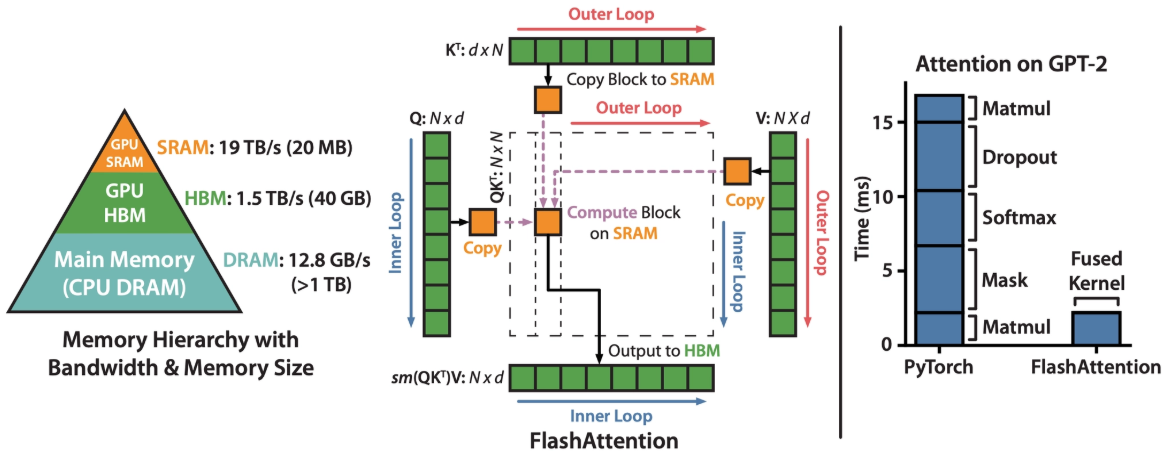
왼쪽부터 GPU 메모리 계층 구조, FlashAttention의 블록 단위 처리 방식, 기존 PyTorch 대비 속도 비교. FlashAttention은 Q, K, V를 블록 단위로 SRAM에 올려 한꺼번에 처리함으로써 HBM 왕복을 줄인다. GPT-2 기준 기존 대비 약 5배 빠른 속도를 보여준다. 출처: <FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness> (Dao et al., 2022)
FlashAttention의 아이디어는 간단합니다. Q, K, V를 SRAM에 들어갈 만큼 작은 블록으로 나누고, 각 블록 안에서 QKᵀ → Softmax → V곱을 한꺼번에 처리하고 최종 결과만 HBM으로 보내는 것입니다. 세 번의 왕복이 한 번으로 줄어드는 것입니다.
어려움을 극복하기 위한 Online Softmax
블록 단위로 처리하면 속도는 빨라지지만, Softmax를 올바르게 계산하는 것이 까다로워집니다. Softmax의 분모에는 전체 토큰에 대한 지수 값의 합이 필요하고, 수치 안정성을 위해 해당 토큰의 모든 Attention Score 중 최댓값도 알아야 하기 때문입니다. 하나의 블록 내 정보만으로는 이 값들을 알 수 없습니다.
예를 들어 시퀀스가 8개 토큰이고 블록 크기가 4라면, Q, K, V를 각각 두 블록으로 나누어 처리합니다. 첫 번째 블록(K₁)을 처리할 때 행의 최댓값을 m₁ = 4.1로 구했는데, 두 번째 블록(K₂)에서 5.0이라는 더 큰 값이 나타날 수 있습니다. 이러면 첫 번째 블록의 계산 결과를 보정해야 합니다.
FlashAttention은 이를 Online Softmax 알고리즘으로 해결합니다. 핵심은 Softmax에서 빼는 상수를 바꿔도 지수 스케일링으로 변환할 수 있다는 성질입니다.
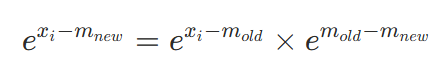
새로운 최댓값이 발견되면, 이전 블록의 결과에 exp(m_old - m_new)를 곱해서 보정하면 됩니다. 전체 데이터를 한 번에 볼 필요 없이, 블록을 처리할 때마다 최댓값과 지수 합을 갱신하면서 이전 결과를 보정해 나가는 것입니다.
이렇게 블록별로 계산하고 보정한 결과는 처음부터 전체에 Softmax를 적용한 것과 수학적으로 완전히 동일합니다. 이로써 N×N의 거대한 Attention Score 행렬을 메모리에 올리지 않으면서도 정확한 결과를 얻을 수 있는 것입니다.
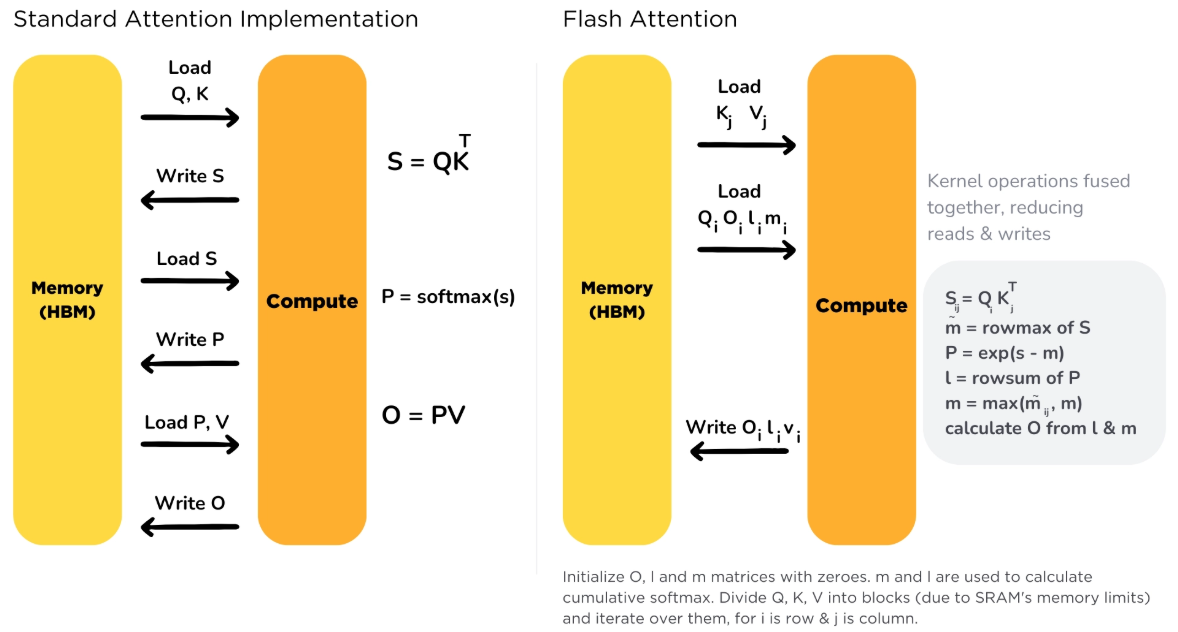
기존 Attention 구현(왼쪽)은 행렬곱, Softmax, V곱 각 단계마다 HBM과 연산 유닛 사이를 왕복한다. FlashAttention(오른쪽)은 이 연산들을 하나의 커널로 융합하여 왕복 횟수를 줄인다. 오른쪽 회색 박스의 수식이 블록 단위로 SRAM 안에서 한꺼번에 처리되는 Online Softmax 과정이다. 출처: HuggingFace, Text Generation Inference - Flash Attention
💡
Online Softmax
Online Softmax는 전체 데이터를 한 번에 보지 않고, 블록이 들어올 때마다 최댓값과 지수 합을 바로 갱신하면서 Softmax를 계산하는 알고리즘입니다. NVIDIA의 Milakov & Gimelshein(2018)이 제안했으며, FlashAttention은 이를 블록 단위 Attention 계산에 적용했습니다.
FlashAttention의 진화: 1에서 4까지
FlashAttention은 ‘블록 단위 타일링과 Online Softmax’이라는 핵심 아이디어를 유지하면서, GPU 하드웨어의 변화에 맞춰 진화해 왔습니다. 각 버전의 주요 변화를 정리하면 다음과 같습니다.
**FlashAttention-1(2022)**은 IO-aware 타일링이라는 핵심 아이디어를 처음 제안했습니다. Q, K, V를 블록 단위로 나누어 SRAM 안에서 Attention을 한 번에 계산함으로써 HBM 접근을 최소화했습니다. 이를 통해 기존 대비 메모리 사용량을 시퀀스 길이에 비례(선형)하는 수준으로 줄이면서도 속도를 높였습니다. 다만, GPU 하드웨어 활용률은 이론적 최대치의 25~40%에 머물렀습니다.
**FlashAttention-2(2023)**는 GPU 활용률을 끌어올리는 데 집중했습니다. 시퀀스 길이뿐 아니라 배치(Batch)와 헤드(Head) 차원에서도 병렬 처리를 가능하게 하고, Softmax 보정 과정에서 발생하는 비행렬곱(non-matmul) 연산을 줄여 A100 GPU에서 최대 73% 활용률을 달성했습니다.
**FlashAttention-3(2024)**는 NVIDIA Hopper GPU(H100)의 새로운 하드웨어 기능을 활용했습니다. 텐서 코어와 데이터 이동을 비동기적으로 실행하여 연산과 메모리 전송을 겹치고, FP8 저정밀도 연산을 지원했습니다. H100에서 최대 840 TFLOPs/s(85% 활용률)를 달성했습니다.
그리고 올해 3월, FlashAttention-4가 공개되었습니다. FlashAttention-4는 Blackwell GPU(B200)의 비대칭 스케일링 문제에 대응합니다.
FA4 논문의 부제는 "Algorithm and Kernel Pipelining Co-Design for Asymmetric Hardware Scaling"인데요, 여기서 Co-Design이란 하드웨어 특성에 맞춰 알고리즘을 설계한다는 뜻입니다. 하드웨어가 바뀌면 기존 알고리즘을 그대로 쓰는 게 아니라, 새로운 하드웨어의 강점과 약점에 맞춰 알고리즘 자체를 다시 설계하는 것이죠. 반대로 AI 워크로드 특성에 맞춰 NVIDIA가 하드웨어를 설계하는 것도 Co-Design이죠.
그렇다면 FlashAttention-4는 어떤 하드웨어 변화에 대응한 것일까요?
FlashAttention-4의 핵심: Softmax의 지수 함수를 우회하다
AI 업계는 빠르게 NVIDIA Blackwell GPU(B200)로 이동하고 있습니다. Blackwell은 이전 세대인 Hopper에 비해 텐서 코어 처리량이 2.25배 증가했습니다. 그런데 Softmax의 지수 함수를 처리하는 SFU(Special Function Unit)와 공유 메모리 대역폭은 거의 변하지 않았습니다. 텐서 코어만 빨라지고 나머지는 그대로인 것이죠. 이를 **비대칭 스케일링(Asymmetric Scaling)**이라고 합니다.
Hopper에서는 문제 없던 exp(x)가, Blackwell에서는 병목이 되었습니다. 텐서 코어가 빨라진 만큼 행렬곱은 더 빨리 끝나는데, Softmax의 exp 연산은 같은 속도로 처리됩니다. FlashAttention-3까지는 이 간극이 크지 않았지만, Blackwell 세대에서는 SFU가 명확한 병목이 되었습니다.
FlashAttention-4는 SFU에서 exp(x)를 직접 계산하는 대신, 다항식 근사(Polynomial Approximation)로 FMA(Fused Multiply-Add) 유닛에서 처리합니다. FMA 유닛은 텐서 코어와 병렬로 동작할 수 있어서, 한 블록의 행렬곱을 수행하는 동안 이전 블록의 Softmax를 동시에 처리할 수 있습니다. 기존에는 "행렬곱 → exp → 다음 행렬곱"이 순차적으로 일어났다면, 이제는 이 과정이 겹쳐서 실행되는 것입니다.
또한, Online Softmax의 보정에는 exp 연산이 필요하기 때문에 SFU를 다시 사용해야 합니다. 그런데 실제로는 새 블록에서 더 큰 최댓값이 나타나지 않는 경우도 많습니다. m_new ≤ m_old이면 보정할 필요가 없습니다. FlashAttention-4는 이 경우를 감지하여 보정 자체를 생략하여 SFU 사용을 더 줄였습니다.
결과적으로, FlashAttention-4는 Blackwell B200에서 BF16 기준 최대 1,613 TFLOPs/s, 71%의 하드웨어 활용률을 달성했습니다. FlashAttention-2 시점에서 Attention 연산의 하드웨어 활용률이 25~40%에 불과했던 것을 감안하면, 71%까지 끌어올린 것은 최적화된 행렬곱(GEMM)의 80~90%에 근접하는 수준입니다.
💡
TFLOPs/s(Tera Floating Point Operations per Second)
1초에 수행할 수 있는 부동소수점 연산 횟수를 나타내는 단위로, GPU의 연산 성능을 측정하는 데 사용됩니다. 참고로 B200 GPU의 이론적 최대 성능은 약 2,250 TFLOPs/s이며, FlashAttention-4의 1,613 TFLOPs/s는 최대 성능의 71%입니다.
다만 FA4는 아직 베타 단계이며, BF16만 지원하여 Blackwell의 FP4, FP8 같은 저정밀도 연산은 아직 활용하지 못합니다. 대다수 환경에서는 여전히 FA3가 표준입니다. FA4는 현재의 성과보다는 앞으로의 방향성을 보여주는 것에 가깝습니다.
다양한 추론 최적화 흐름
지금 LLM의 최적화 흐름은 '어디를 병목으로 정의하냐'에 따라 전략이 갈라지고 있습니다. FlashAttention은 Transformer 구조를 바꾸지 않고, Softmax를 유지하면서 Attention을 '어떻게 계산하느냐'에 집중했습니다. 하지만 이것만이 유일한 방향은 아닙니다.
① Softmax 자체를 없애려는 방향도 있습니다. Softmax를 제거하고 선형 함수로 대체하는 Linear Attention은 O(N²)인 복잡도를 O(N)으로 줄일 수 있다는 점에서 매력적이었지만, 특정 토큰에 집중하는 능력이 약해져 실제 성능이 기대에 미치지 못했습니다. 최근에는 게이팅을 추가해 토큰별 기여도를 동적으로 조절하는 Gated Linear Attention(GLA)이나, RWKV처럼 Attention을 변형한 접근, Mamba처럼 Attention 자체를 대체하려는 시도가 이 격차를 점차 좁혀가고 있습니다.
② Attention 구조 자체를 바꾸려는 방향도 활발합니다. DeepSeek이 제안한 **Native Sparse Attention(NSA)**은 아예 모든 토큰을 다 보지 않는 접근입니다. 모든 토큰 쌍을 보는 대신 중요한 토큰만 선별하여 Attention을 계산합니다. 학습 단계부터 적용 가능하고 GPU 하드웨어에 맞게 설계된 것이 특징입니다.
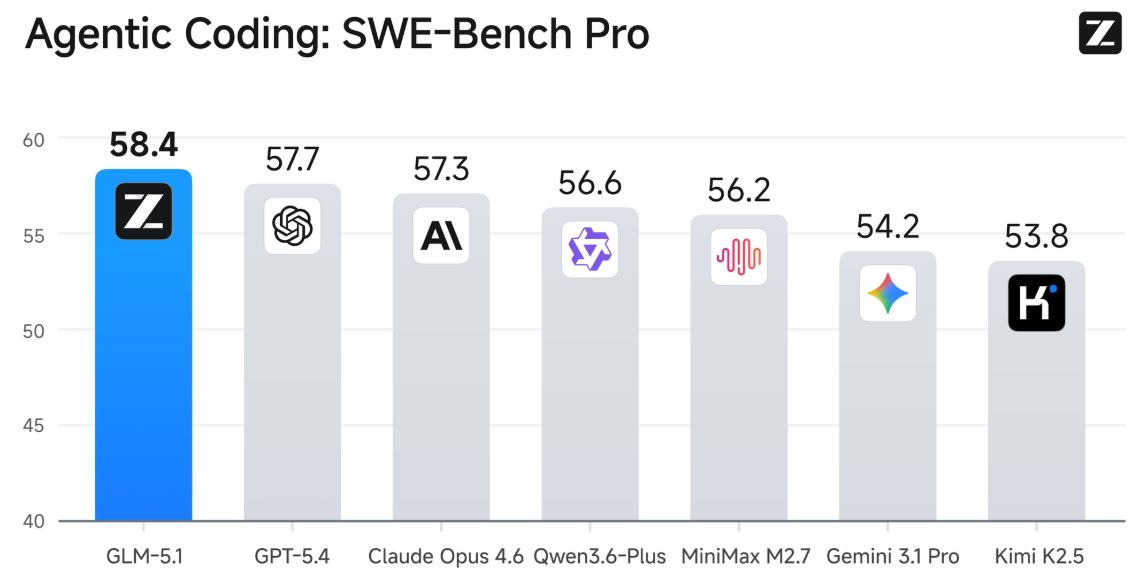
올해 2월 공개된 Z.ai의 GLM-5(744B)도 **Native Sparse Attention(NSA)**을 채택했다. 지난주 공개된 GLM-5.1도 같은 아키텍처 위에서 SWE-Bench Pro 1위를 달성하며 프론티어급 성능을 보여주며 주목받고 있다. 출처: GLM-5.1 (Z.ai 공식 문서)
③ KV Cache를 압축하는 방향도 있습니다. LLM은 이전 토큰들의 Key와 Value를 메모리에 KV Cache로 저장해두는데, 시퀀스가 길어질수록 이 캐시가 GPU 메모리를 크게 차지합니다. DeepSeek-V2에서 도입된 MLA(Multi-Head Latent Attention)는 각 헤드의 Key, Value를 그대로 저장하지 않고 저차원 행렬을 사용해 하나의 저차원 잠재 벡터로 압축하여 캐시에 저장하고, 필요할 때 복원하는 방식으로 KV Cache 메모리를 최대 93.3%까지 줄였습니다. DeepSeek-V2에서 처음 적용된 이후 DeepSeek-V3를 거쳐 현재까지 이어지고 있는 핵심 기술입니다.
모델 아키텍처를 바꾸지 않고 KV Cache를 줄이는 연구도 활발합니다. 지난 6일 MIT와 NVIDIA가 발표한 TriAttention은 캐시에서 어떤 토큰을 유지하고 어떤 토큰을 버릴지를 효율적으로 판단하여 KV 메모리를 약 10배 절감하면서도 추론 정확도를 유지했습니다.
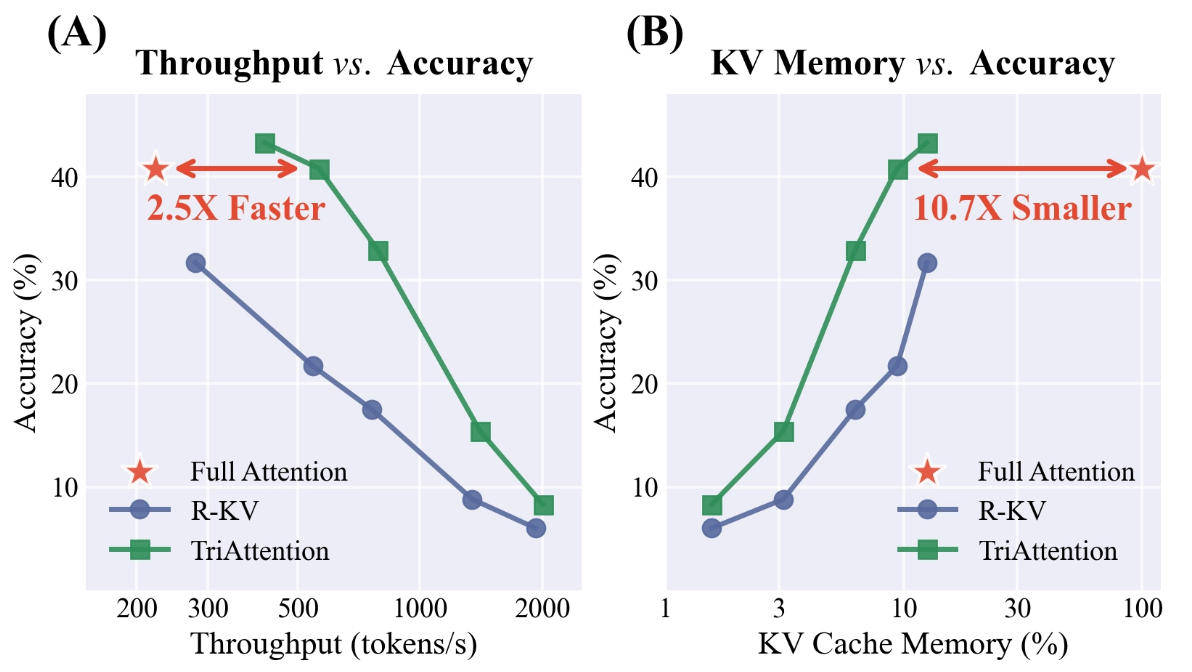
동일한 정확도에서 TriAttention은 Full Attention 대비 2.5배 높은 처리량(왼쪽), 또는 10.7배 적은 KV 메모리(오른쪽)를 달성한다. 기존 방법(R-KV)은 같은 조건에서 정확도가 크게 떨어진다. 출처: <TriAttention: Efficient Long Reasoning with Trigonometric KV Compression> (Mao et al., 2026)
④ 추론 파이프라인을 재설계하는 방향도 있습니다. LLM은 토큰을 하나씩 순서대로 생성하기 때문에, GPU 연산 능력이 남아도 속도를 올리기 어렵습니다. Speculative Decoding은 이 문제를 우회합니다. 작고 빠른 드래프트 모델이 여러 토큰을 먼저 생성하고, 메인 모델이 이를 한 번의 Forward pass로 일괄 검증하는 방식입니다. 맞으면 채택하고, 틀린 지점부터 교체합니다.
이 분야에서 주목할 만한 연구가 EAGLE 시리즈입니다. EAGLE은 별도의 드래프트 모델 대신 메인 모델의 내부 Hidden state를 활용해 후보 토큰을 예측합니다. 최신 버전인 EAGLE-3는 마지막 레이어만 보던 기존 방식에서 벗어나 하위·중간·상위 레이어의 Feature를 모두 융합하여 예측 정확도를 높였고, 최대 6.5배 속도 향상을 달성했습니다. 현재 vLLM, AWS SageMaker 등 주요 추론 프레임워크에 통합되어 실무에서 활발히 사용되고 있습니다.
이전 뉴스레터에서 다뤘던 Continuous Batching도 추론 파이프라인 최적화의 한 축이죠.
Transformer의 Attention은 그 자체로 뛰어난 메커니즘이지만, 실제 서비스에서 동작시키려면 하드웨어의 특성까지 고려한 정교한 최적화가 필요합니다. FlashAttention 시리즈가 보여주듯, GPU 세대가 바뀔 때마다 병목 지점도 달라지고 그에 맞는 새로운 해법이 등장합니다. 앞으로도 하드웨어와 소프트웨어의 공동 설계(Co-design)는 LLM 추론 효율화의 핵심 키워드가 될 것입니다.
여러분들은 어떤 기술에 관심이 있나요? 여러분들이 연구하고 있거나 관심있는 주제가 있다면 알려주세요.