당신이 쓴 프롬프트, 최선이었을까요?

- 한눈에 보는 핵심요약
- - 프롬프트 최적화 연구가 어떻게 발전해 왔는지 흐름을 정리했습니다.
당신이 쓴 프롬프트, 최선이었을까요?
안녕하세요, 에디터 스더리입니다 :)
생성형 AI를 활용하는 사람이라면 누구나 하루에도 수없이 프롬프트를 입력합니다. 그리고 우리는 같은 모델에 같은 질문을 던져도, 어떻게 묻느냐에 따라 결과가 크게 달라질 수 있다는 것을 경험으로 알고 있죠. 프롬프트가 LLM의 답변 생성 능력을 좌우한다는 것은 여전합니다.
더 좋은 결과를 얻기 위해 프롬프트를 설계하고 다듬는 과정을 프롬프트 엔지니어링이라고 합니다. 프롬프트 엔지니어링의 초기에는 시행착오와 직관이 중요한 역할을 했습니다. 하지만 최근 연구들은 여기서 한 걸음 더 나아갑니다. 그리고 그 과정에서 질문도 바뀌었습니다. ‘좋은 프롬프트는 무엇인가?’에서 ‘좋은 프롬프트를 어떻게 자동으로 찾아낼 수 있는가?’로 말이죠. 오늘은 그 흐름을 처음부터 함께 살펴보겠습니다.
프롬프트 한 줄이 모든 것을 바꿀 수 있다
2022년, 도쿄대와 Google 연구팀은 Large Language Models are Zero-Shot Reasoners(2022)라는 논문을 발표했습니다. 오늘날 Chain-of-Thought 프롬프팅의 출발점으로 자주 언급되는 연구입니다. 핵심 발견은 단순했습니다. LLM에게 어려운 문제를 풀게 할 때, 답을 바로 요구하는 대신 “Let’s think step by step”이라는 문장을 덧붙이는 것만으로도 성능이 크게 향상된다는 것입니다.
지금 보면 당연하게 느껴질 수도 있습니다. 하지만 당시에는 꽤 충격적인 결과였죠. 모델의 구조나 가중치는 전혀 바꾸지 않은 채, 입력 문장 한 줄만 수정했는데도 모델의 추론 능력이 달라졌기 때문입니다. 이 연구는 프롬프트가 단순한 입력을 넘어 모델의 추론 과정을 유도할 수 있다는 가능성을 보여주었습니다. 그리고 자연스럽게 다음 질문으로 이어졌습니다.
그렇다면 더 좋은 프롬프트는 어떻게 찾을 수 있을까?
2023년, 토론토대 연구팀은 APE(Automatic Prompt Engineer; 2023)를 제안했습니다. 핵심 아이디어는 프롬프트 작성 자체를 자동화하는 것이었습니다. 사람이 직접 프롬프트를 만드는 대신, LLM이 여러 후보를 생성하고 실제 성능을 기준으로 가장 효과적인 프롬프트를 선택하는 방식이었죠.
하지만 여기서 또 다른 문제가 드러났습니다. APE는 더 나은 프롬프트를 찾을 수는 있었지만, 그 과정은 여전히 ‘검색’에 가까웠습니다. 다양한 후보를 생성한 뒤 가장 성능이 좋은 프롬프트를 고르는 구조였기 때문에, 탐색해야 할 후보가 많아질수록 비용이 커졌습니다. 무엇보다 왜 어떤 프롬프트는 잘 작동하고, 어떤 프롬프트는 그렇지 않은지는 여전히 알 수 없었죠.
연구자들은 단순히 후보를 고르는 것을 넘어, 프롬프트를 평가하고 수정하며 점진적으로 개선할 수 있는 방법을 고민하기 시작했습니다. 이때부터 프롬프트 최적화 연구는 '검색'에서 '학습'의 단계로 넘어가게 됩니다.
LLM이 스스로 프롬프트를 고치기 시작하다
그 고민에서 나온 연구들이 2024년 전후 본격적으로 등장하기 시작했습니다. 방법은 제각각이었지만 방향은 같았습니다. 프롬프트를 한 번 만들고 끝내는 것이 아니라, 이전 시도의 결과를 바탕으로 다음 시도를 개선하는 것이었습니다.
생각해보면 사람도 비슷하게 배웁니다. 한 번 틀리면 그 방식을 기억하고, 다음에는 다른 방법을 시도하죠. 그 과정에서 중요한 것은 피드백입니다. 무엇이 잘됐고 무엇이 잘못됐는지 알아야 다음 시도를 개선할 수 있으니까요. 연구자들이 던진 질문도 크게 다르지 않았습니다.
이전 시도에서 무언가를 배울 수 있지 않을까?
DeepMind가 발표한 OPRO(Optimization by PROmpting; 2024)는 이 질문에 꽤 직접적으로 답했습니다. LLM에게 지금까지 시도한 프롬프트들과 각각의 성능 점수를 보여주면서, “이 기록을 참고해서 더 나은 프롬프트를 제안해봐”라고 요청하는 방식이었습니다. 흥미로운 점은 여기서 LLM이 단순한 생성기가 아니라 옵티마이저(Optimizer)의 역할을 맡았다는 것입니다. 과거의 성공과 실패를 참고해 다음 시도를 개선한다는 점에서, APE보다 한 단계 더 발전된 접근이었습니다.
EvoPrompt(2024)는 같은 질문을 진화라는 관점에서 풀어냈습니다. 여러 프롬프트를 하나의 개체(Population)로 보고, 성능이 좋은 프롬프트를 부모로 선택한 뒤 새로운 프롬프트를 만들어내는 방식이었습니다. 예를 들어 "문장의 감성을 판단하라"와 "positive 또는 negative 라벨만 출력하라"라는 두 프롬프트가 있다면, 이들을 조합해 "문장의 감성을 판단하고 positive 또는 negative 라벨을 출력하라"와 같은 새로운 프롬프트를 생성합니다. 이를 교배(Crossover)라고 부릅니다. 이어서 일부 표현을 조금씩 수정하는 돌연변이(Mutation) 과정을 거친 뒤, 생성된 프롬프트들을 같은 문제에 적용해 어떤 프롬프트가 더 높은 정확도를 내는지 평가합니다. 그렇게 성능이 좋은 프롬프트만 다음 세대로 넘기고, 그렇지 않은 프롬프트는 제거하면서 자연선택처럼 점차 더 나은 프롬프트를 찾아가는 것이죠.
Microsoft 연구팀의 ProTeGi(2023)는 성능 점수 대신 모델이 실제로 실패한 사례에 주목했습니다. 예를 들어 감성 분석 문제에서 "이 영화는 별로였다"라는 문장을 긍정으로 분류했다면, 단순히 정확도가 낮다는 점수만 출력하는 대신 "프롬프트가 부정 표현을 충분히 고려하지 못하고 있다"는 자연어 비판을 생성합니다. 이후 이 비판을 바탕으로 프롬프트를 수정하고 다시 평가하는 과정을 반복합니다. 즉, 숫자로 된 점수 대신 실패 원인 자체를 피드백으로 활용해 프롬프트를 개선하려는 시도입니다.
방법은 달랐지만, 이 연구들은 모두 과거 시도의 결과를 활용해 프롬프트를 점진적으로 개선하려 했다는 공통점이 있었습니다. 점수든, 진화 과정이든, 자연어 비판이든 결국 목표는 더 좋은 프롬프트를 만드는 것이었습니다. 그런데 생각해보면, 최적화할 수 있는 대상은 프롬프트 하나에만 한정되지 않습니다. 프롬프트는 결국 시스템 안에서 하나의 구성 요소일 뿐이고, 그 밖에도 답변 생성 방식이나 추론 과정처럼 조정 가능한 부분들이 존재합니다. 그렇다면 언어로 된 피드백을 프롬프트를 넘어 더 넓은 최적화 과정에 활용할 수는 없을까요?
텍스트를 학습한다면
TextGrad(2025)는 여기서 한 걸음 더 나아갑니다. 앞선 연구들이 더 좋은 프롬프트를 찾는 데 집중했다면, TextGrad는 프롬프트뿐 아니라 답변, 추론 과정, 코드 등 텍스트로 표현 가능한 모든 요소를 최적화 대상으로 확장합니다.
프롬프트 엔지니어링의 관점에서 생각해보면, 우리가 궁극적으로 알고 싶은 것은 결국 ‘더 좋은 평가를 받기 위해 프롬프트를 어떻게 수정해야 하는가?’ 입니다. 저자들은 이를 역전파(Backpropagation) 문제로 재정의합니다. 딥러닝에서 Gradient가 손실을 줄이기 위한 업데이트 방향을 제공하듯, 프롬프트 최적화 역시 평가 결과를 개선하기 위한 업데이트 방향을 찾는 과정으로 볼 수 있다는 것이죠. 이러한 관점에서 보면 우리가 구하고 싶은 것은 프롬프트를 어느 방향으로 수정해야 평가가 개선되는지를 알려주는 값, 즉 ∂Evaluation / ∂Prompt입니다.
문제는 LLM 기반 시스템에서는 이 값을 직접 계산할 수 없다는 점입니다. 딥러닝에서는 모델 전체가 하나의 미분 가능한 계산 그래프로 연결되어 있기 때문에 Gradient를 계산할 수 있습니다. 반면 LLM 시스템은 자연어 프롬프트, 생성된 답변, 외부 도구 호출 등이 얽혀 있어 ∂Evaluation / ∂Prompt를 직접 계산하기 어렵습니다.
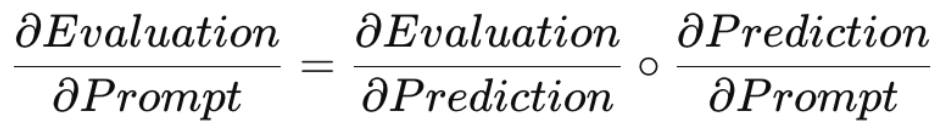
ⓒ deep daiv.
하지만 ∂Evaluation / ∂Prompt를 직접 계산할 수 없다고 해서, 그와 관련된 모든 정보를 얻을 수 없는 것은 아닙니다. 위 그림에서 볼 수 있듯이, 이 값은 연쇄 법칙(Chain Rule)에 의해 다음과 같이 표현할 수 있습니다. 즉, 답변이 평가에 미치는 영향(∂Evaluation / ∂Prediction)과 프롬프트가 답변(Prediction)에 미치는 영향(∂Prediction / ∂Prompt)을 알 수 있다면, 궁극적으로 우리가 원하는 프롬프트의 수정 방향도 추론할 수 있습니다.
TextGrad의 핵심 아이디어는 이 과정을 자연어 피드백으로 구현하는 것입니다. 다시 말해, 답변에 대해 ‘무엇이 잘못되었는지’와 ‘어떻게 수정해야 하는지’를 설명한 비판(Critique)을 업데이트 방향을 알려주는 신호로 활용하는 것이죠.
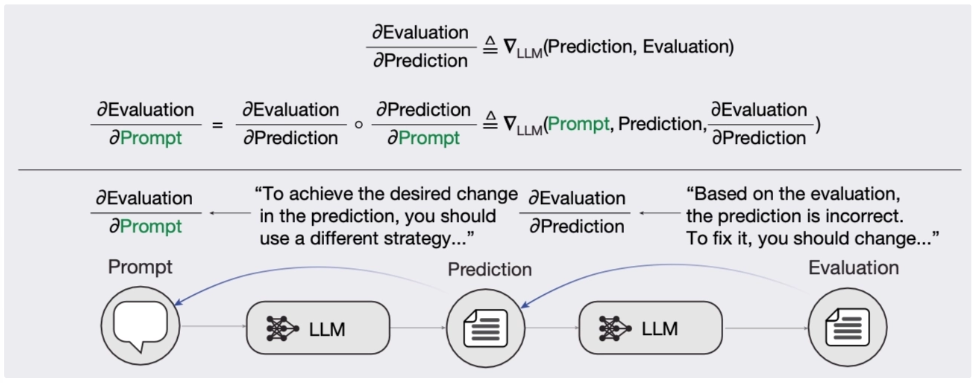
출처: Optimizing generative AI by backpropagating language model feedback (Yuksekgonul et al., 2025)
먼저 LLM이 프롬프트를 받아 답변(Prediction)을 생성합니다. 그러면 평가 LLM이 그 답변을 보고 "Based on the evaluation, the prediction is incorrect. To fix it, you should change..."와 같이 무엇이 잘못됐는지를 자연어로 설명합니다. 이것이 ∂Evaluation / ∂Prediction에 해당합니다. 그리고 이 비판을 바탕으로, 이런 답변을 만들어낸 프롬프트는 어떻게 바꿔야 하는지를 추론합니다. 답변 수정 방향에 대한 정보를 프롬프트 수정 방향으로 전파하는 것이죠. 이렇게 두 단계를 결합해 궁극적으로 ∂Evaluation / ∂Prompt를 근사합니다. 숫자가 아닌 언어를 사용한다는 점만 다를 뿐, 출력의 오류를 앞단으로 전달해 수정 방향을 찾는다는 점에서는 역전파와 매우 유사한 구조입니다.
연구팀은 이를 다양한 영역에서 검증했습니다. GPQA(PhD 수준 과학 문제 벤치마크)에서 GPT-4o의 정확도는 51%에서 55%로 향상되었고, LeetCode Hard 문제에서도 대표적인 자기개선 기법인 Reflexion의 31%를 넘어 36%의 정답률을 기록했습니다. 신약 후보 분자 최적화나 방사선 치료 계획 설계와 같은 복잡한 과제에서도 동일한 프레임워크를 적용할 수 있었습니다. 텍스트로 표현할 수 있는 것이라면, 무엇이든 최적화의 대상이 될 수 있는 것이죠.
반성하고, 진화하고, 더 나아지다
TextGrad가 언어 피드백을 활용해 텍스트로 표현 가능한 모든 구성 요소를 최적화하는 범용 프레임워크를 제안했다면, UC Berkeley, Stanford, MIT 연구팀이 발표한 GEPA(2026)는 조금 다른 질문에서 출발합니다.
더 적은 시도로, 더 좋은 프롬프트를 찾을 수 있을까?
GEPA는 Genetic Pareto의 약자로, 반성과 진화를 결합한 프레임워크입니다. 먼저 AI 시스템을 실행한 뒤, 생성 과정과 최종 평가 결과를 함께 분석합니다. 이후 LLM은 어떤 프롬프트가 성공 또는 실패에 기여했는지, 그리고 이를 어떻게 개선할 수 있는지를 자연어로 정리합니다. 일종의 오답 노트처럼요.
GEPA는 이렇게 생성된 결과(Reflection)를 바탕으로 새로운 프롬프트 후보를 생성하고 진화시킵니다. 앞서 살펴본 EvoPrompt도 진화 알고리즘을 활용했지만, 프롬프트의 성능 점수만을 기준으로 교배와 변이를 반복했습니다. 반면 GEPA는 왜 실패했는지를 먼저 언어로 분석하고, 이를 바탕으로 다음 후보를 생성합니다.
이러한 Reflection은 탐색 방향에 대한 힌트를 제공하기 때문에, 훨씬 적은 시도로 더 빠르게 좋은 프롬프트에 도달할 수 있게 합니다. 또한 GEPA는 Pareto 최적화를 활용해 하나의 기준에서만 치우치지 않고 여러 지표를 동시에 고려합니다. 덕분에 다양한 상황에서 안정적으로 잘 작동하는 프롬프트를 찾을 수 있습니다.
이러한 설계는 실제 성능 향상으로도 이어졌습니다. 당시 최고 성능의 프롬프트 최적화 방법이었던 MIPROv2를 10% 이상 능가했고, RL 기반 방법 대비 평균 6% 성능 향상을 내면서 시도 횟수는 최대 35배 적게 사용했습니다.
2022년, 우리는 좋은 프롬프트가 무엇인지를 물었습니다. 불과 몇 년 만에 그 질문은 완전히 달라졌고, 이제는 시스템이 스스로 반성하고 진화하며 더 나은 프롬프트를 찾아가는 단계에 이르렀습니다.
처음 ChatGPT가 등장했을 때, 프롬프트를 잘 쓰는 능력은 하나의 중요한 역량처럼 여겨졌습니다. 하지만 오늘 살펴본 연구들을 보면, 프롬프트를 개선하고 탐색하는 과정은 이미 상당 부분 자동화되기 시작했습니다. 그렇다면 사람의 역할은 무엇일까요. 시스템이 스스로 프롬프트를 찾아가는 시대일수록 무엇을 최적화할지, 그리고 어떤 결과를 ‘좋은 결과’로 정의할지가 더 중요해질 것입니다.
추천 콘텐츠
관련 콘텐츠가 없습니다.