광고 AI 에이전트 서비스 – 광고 성과 분석 및 자동 최적화 설계
💌 BizSpring에서 제공하는 최신 마케팅 트렌드를 받아보고 싶다면, 뉴스레터를 구독해 주세요.!
다양한 인사이트 정보에서 활용방법, 최신 트렌드 정보를 매월 보내드립니다!

특히 광고 분야에서는 실시간 성과 분석과 자동 최적화를 통해 광고 캠페인의 ROI를 극대화하는 데 큰 기여를 할 수 있습니다. 이번 글에서는 실시간 광고 성과를 분석하고, 타겟팅 및 예산 배분을 자동으로 최적화하는 AI 에이전트의 설계 원리를 제시하고자 합니다.
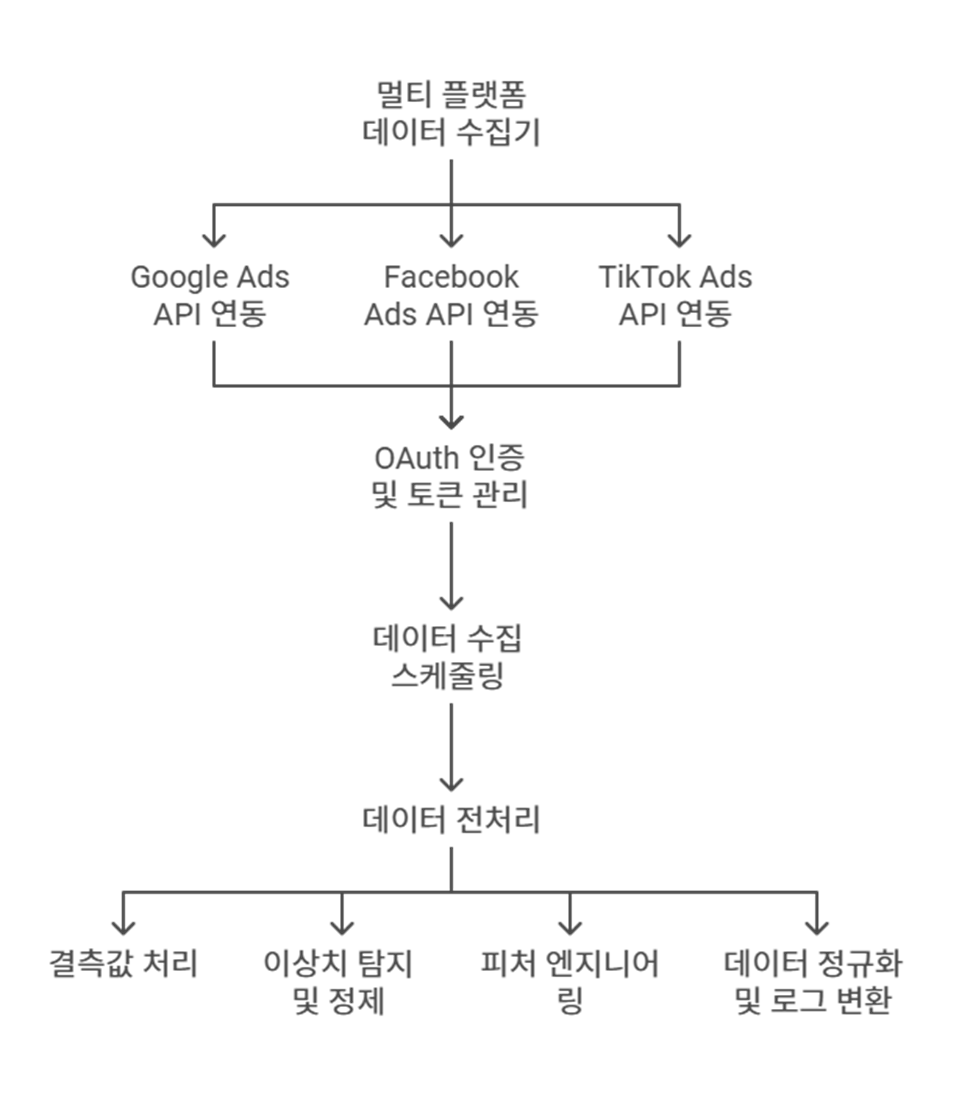
1. 광고 데이터 수집 및 전처리
- 실시간 데이터 수집
- 광고 플랫폼 API 연동: Google Ads, Facebook Ads, TikTok Ads 등 주요 광고 플랫폼에서 제공하는 API를 활용하여 실시간으로 광고 성과 데이터를 수집합니다. 각 플랫폼의 실시간 데이터를 수집 주기에 맞춰 자동으로 수집하고, 정기적인 API 호출을 통해 광고 성과 데이터를 계속해서 업데이트합니다.
- 예: 노출 수, 클릭률(CTR), 전환율(CVR), 광고비용(Cost), ROI (Return on Investment), ROAS (Return on Ad Spend)
- 데이터 전처리
- 이상치 및 결측값 처리: 수집된 데이터를 분석하기 전에 결측값(Missing Data)이나 이상치(Outlier)를 식별하고, 이를 보정합니다. 결측값은 평균 대체, 예측 모델을 사용한 보정, 또는 삭제 방법을 통해 처리할 수 있습니다.
- 데이터 변환:
- 로그 변환: 비용, 클릭수, 노출수 등의 값이 크게 분포할 때, 로그 변환을 통해 분포를 안정화시킵니다.
- 정규화(Normalization): 각 지표가 동일한 범위를 가지도록 정규화하여 모델 학습을 용이하게 만듭니다.
- 피처 엔지니어링: 시간대, 캠페인 유형, 디바이스 종류, 지역 등 다양한 사용자 속성을 기준으로 특성을 추출하여 모델 학습에 필요한 피처를 생성합니다.
- 세분화 분석: 캠페인별, 디바이스별, 시간대별 성과를 분석하여 추가적인 피처를 생성합니다.
2. AI 모델 학습 및 최적화
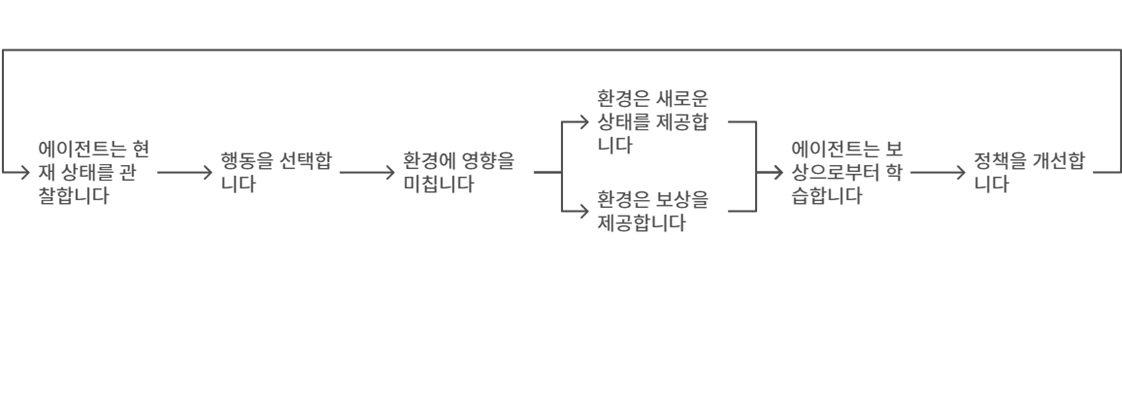
- 강화 학습 모델 설계 : 상태, 행동, 보상 체계를 명확히 정의하여 AI 에이전트의 의사결정 프레임워크 구축한다.
- 상태(State): 광고 캠페인의 현재 상태를 정의합니다. (예: 타겟팅, 예산 배분, 광고 소재 등)
- 행동(Action): AI 에이전트가 취할 수 있는 행동을 정의합니다. (예: 타겟 확장, 예산 재배분)
- 보상(Reward): 광고 성과를 평가하는 기준이 됩니다. (예: CTR, CVR, ROAS, ROI 등)
[작동 방식]
- 모델 학습
- 과거 데이터 활용: 광고 캠페인 데이터를 기반으로 과거의 의사결정과 성과를 학습하여 AI 에이전트가 최적의 의사결정을 내릴 수 있도록 합니다.
- 강화 학습 알고리즘:
- DQN(Deep Q-Network): 정책을 추정하는 네트워크를 이용한 Q-Learning 방식
- 상태 공간 정의 : 현재 광고 캠페인 성과 (예: 클릭률, 전환율) , 타겟 세그먼트 특성, 예산 활용도, 플랫폼별 성과 지표
- 의사결정 행동: 예산 재분배 비율 결정, 타겟 세그먼트 확장/축소, 광고 소재 변경 , 입찰 전략 조정
- 보상 함수 설계: ROAS 증가율,CTR 개선도,전환율 향상 정도
- 학습 프로세스: 과거 캠페인 데이터로 신경망 사전 훈련, 각 의사결정에 대한 예상 가치 학습, 탐험(Exploration)과 활용(Exploitation) 균형
- A2C(Advantage Actor-Critic): 행동의 장점을 추정하여 더 나은 행동을 선택하는 방식
- 핵심 메커니즘:
- Actor 네트워크: 최적의 광고 전략 정책 생성, 타겟팅, 예산 배분 정책 학습
- Critic 네트워크: 각 행동의 가치 평가, 정책 개선을 위한 피드백 제공
- 동시 학습:
- Actor: 더 나은 광고 의사결정 정책 탐색
- Critic: 의사결정의 성과 예측 및 평가
- 광고 최적화 예시:
- 특정 연령대 타겟팅의 성과 예측 -> 크리에이티브 소재 변경 효과 평가 -> 플랫폼별 최적 예산 배분 전략 학습
- PPO(Proximal Policy Optimization): 안정적인 정책 업데이트를 통해 성능 향상을 도모하는 방법
- 차별화된 접근법:
- 정책 업데이트 안정성 : 과도한 정책 변경 방지, 점진적이고 안정적인 학습
- 제한된 정책 업데이트 : 현재 정책과 새 정책 간 차이 최소화, 급격한 성과 변동 방지
- 광고 캠페인 적용:
- 장기적 광고 성과 개선 , 점진적 타겟팅 전략 최적화 , 예산 배분의 안정적 조정
-> DQN, A2C, PPO 등 다양한 강화학습 알고리즘을 활용하여 광고 성과를 동적으로 최적화합니다.
- 하이퍼파라미터 튜닝
- 튜닝 방법: 각 알고리즘의 성능을 최적화하기 위해 그리드 서치(Grid Search) 또는 베이지안 최적화 기법을 사용하여 하이퍼파라미터를 조정합니다.
- 모델 성능 평가: 모델이 학습하는 동안, **교차 검증(Cross-Validation)**을 통해 모델의 성능을 평가하고, **과적합(Overfitting)**을 방지합니다.
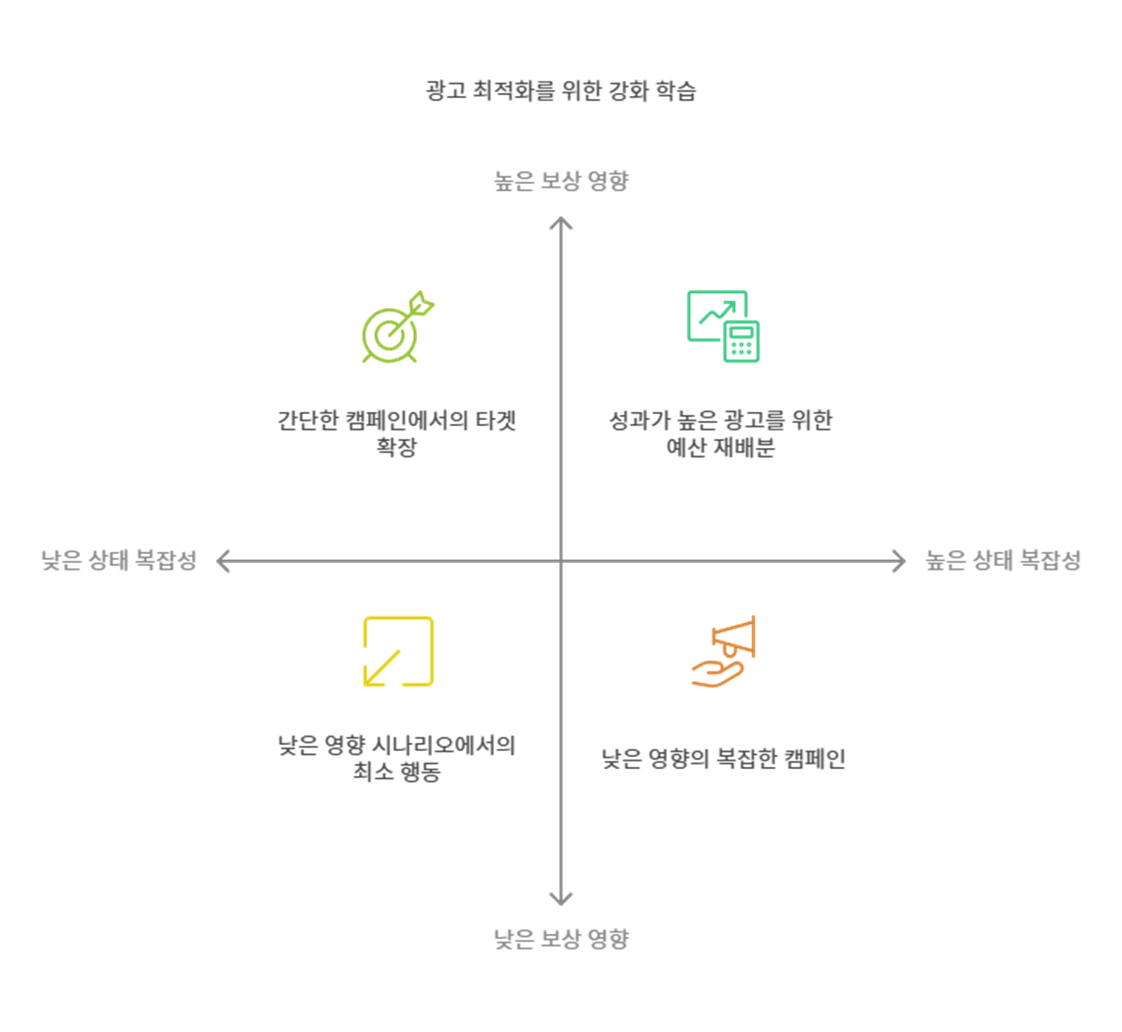
3. 실시간 최적화 및 자동화
- 실시간 성과 분석
- 데이터 스트리밍: 실시간 광고 성과 데이터가 플랫폼에서 지속적으로 업데이트될 때마다, Apache Kafka나 Apache Flink와 같은 데이터 스트리밍 기술을 사용하여 실시간 데이터 흐름을 처리하고 분석합니다.
- 성능 평가 지표: 실시간으로 광고 성과를 분석하고, ROAS나 CTR과 같은 실시간 지표를 기준으로 캠페인 성과를 평가합니다.
- 자동 최적화
- 자동화된 의사결정: AI 모델을 통해 실시간으로 타겟팅(예: 연령대, 지역, 디바이스)과 예산 배분을 최적화합니다.
- 타겟팅 최적화: 특정 타겟군에서 성과가 좋다면 그 타겟군을 확장하거나 세분화하여 새로운 세그먼트를 정의합니다.
- 예산 자동 재분배: 성과가 좋은 캠페인에 예산을 집중시키고, 성과가 낮은 캠페인의 예산을 감소시킵니다.
- 실시간 입찰가 최적화: 입찰가를 실시간으로 조정하여 광고 예산을 효율적으로 활용합니다.
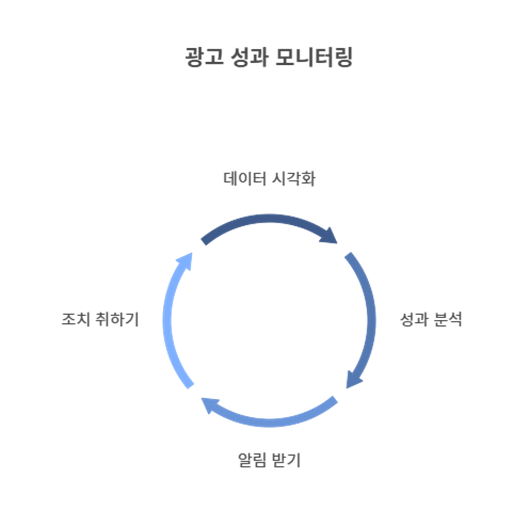
- 성과 모니터링 및 시각화
- 대시보드: 실시간 성과를 시각화하여 광고 캠페인의 변화를 쉽게 모니터링할 수 있는 대시보드를 구축합니다. Tableau나 Power BI와 같은 도구를 사용하여 광고 성과를 실시간으로 시각화하고, 필요한 조치를 즉각적으로 취할 수 있도록 지원합니다.
- 알림 시스템: 성과가 급격히 변화할 때, 예를 들어 클릭률이 급격히 떨어지거나 ROAS가 낮아졌을 때 즉시 알림을 통해 대응할 수 있도록 시스템을 구축합니다.
4. 지속적인 학습 및 개선
- 피드백 루프
-성능 피드백: 광고 캠페인에서 발생하는 실시간 데이터를 통해 AI 에이전트는 성과를 평가하고 피드백을 학습하여 의사결정을 지속적으로 개선합니다.
- 모델 재학습
- 주기적 재학습: 광고 캠페인 데이터를 주기적으로 학습하여 최신 트렌드와 광고 시장 변화를 반영합니다. 새로운 데이터가 축적됨에 따라 모델을 주기적으로 재학습하여 성능을 개선합니다.
- A/B 테스트
- 알고리즘 비교: 새로운 알고리즘이나 최적화 전략을 A/B 테스트를 통해 검증하고, 성능 향상을 도모합니다. 예를 들어, 기존의 예산 최적화 방법과 새로운 알고리즘을 비교하여 성과가 더 좋은 방법을 선택합니다.
위와 같은 설계 원리를 활용하면 실시간 광고 성과 분석 및 자동 최적화 AI 에이전트를 효과적으로 구축할 수 있습니다. 이 시스템은 광고 캠페인의 효율성을 극대화하고, 실시간으로 변화하는 데이터에 유연하게 대응하며, 비즈니스 성과를 지속적으로 향상시킬 수 있습니다.
비즈스프링은 AI 에이전트 구현을 위한 다양한 환경에서의 데이터 수집 -> 가공 -> 적재 서비스와 AI 솔루션 구축 서비스를 제공하고 있으니
관련하여 궁금한 사항 및 문의 사항이 있으시다면 언제든 편하게 연락 주시길 바랍니다. 👉 서비스 문의하기
✔️ 데이터엔지니어링을 위한 구글 빅쿼리(BigQuery) 이용 사례
추천 콘텐츠
관련 콘텐츠가 없습니다.