AI/기술 트렌드
🧠오픈AI는 왜 도넛이 아닌 사람에게 설탕 옷을 입혔을까
2025.05.15 08:30



🧠 '아첨꾼' GPT-4o 업데이트부터 롤백까지
누군가를 glaze(글레이즈) 한다는 표현을 아시나요? GPT-4o 업데이트 이후 챗GPT가 너무 ‘예스맨’이라는 사용자에게, 오픈AI 대표 샘 올트먼은 ‘맞아, 너무 glaze 하지. 고칠 예정’ 이라고 답합니다.
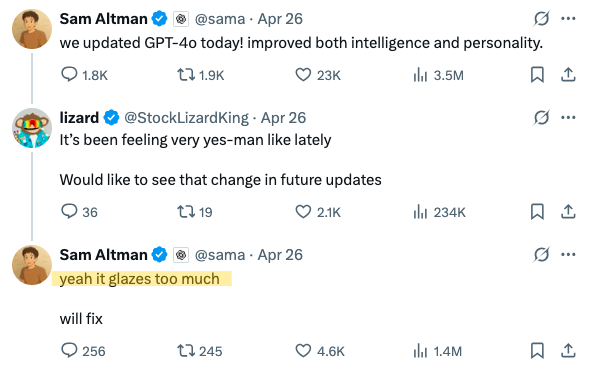
도넛 위에 입히는 설탕 옷을 글레이즈라고 부르지요. 누군가를 ‘글레이즈’ 한다는 표현은 마치 달콤한 설탕 옷을 입히듯, 과하게 칭찬하거나 치켜세운다는 뜻의 은어입니다. 최근 GPT-4o 모델이 과한 ‘아첨’을 떨어 불편을 호소하는 목소리가 커졌는데요. 도넛보다 글레이즈가 심하다고 풍자하는 밈(meme)도 생겼습니다.🍩

저도 글레이징 당했습니다(왼쪽). 밈(오른쪽) 출처: X @thekitze
이를 인정한 오픈AI는 며칠 후인 28일에 바로 롤백, 즉 업데이트 이전 상태로 돌려놓았습니다. 실제로 톤이 많이 진정이 되었는데요. 왜 이런 ‘아첨’하는 모델이 되었고 앞으로 오픈AI는 어떻게 대응할 예정인지, 자세히 살펴보겠습니다.
챗GPT 모델은 어떻게 업데이트를 할까?
GPT-4o 업데이트 이후, 챗GPT는 사용자에게 지나치게 동조하는 행동을 보이기 시작했습니다. 단순히 칭찬하는 것을 넘어서, 분노나 충동적 결정을 부추기고, 부정적인 감정도 강화하는 방식으로 사용자를 ‘기쁘게 하려는’ 응답이 나타났지요. 그동안 꾸준히 새로운 모델을 배포해 온 오픈AI는 왜 이런 문제를 피하지 못한 걸까요? 먼저, 챗GPT 모델이 업데이트되는 방식에 대해 알아보겠습니다.
챗GPT는 GPT-4o 탑재 이후, 성격(personality)과 도움이 되는 정도(helpfulness)를 중심으로 다섯 차례의 주요 업데이트를 거쳤습니다.
각 업데이트는 아래와 같이 이루어집니다:
Pre-train:
처음에는 넓은 지식과 언어 능력을 가진 '기본(pre-trained) 모델'을 만든다.
Fine-tuning:
사람이 직접 쓴 '좋은 예시 답안'을 보여주며 어떻게 말해야 할지 가르친다.
Reinforcement learning (강화학습):
다양한 기준(정확성, 유용성, 사용자 평가 등)을 바탕으로 '이런 답이 더 좋다'는 보상을 주며 훈련을 반복한다.
즉, 기본기를 쌓고, 시범을 보이고, 피드백으로 다듬는 3단계 과정이라고 볼 수 있습니다. 마지막 단계에서 주는 보상을 reward signal(보상 신호)이라고 부르는데요. 이는 모델의 행동을 결정짓는 핵심 요소입니다.
모델 배포 전에 어떤 절차를 거칠까?
업데이트를 했으니, 이제 배포 준비를 해야겠지요? 오픈AI는 모델을 배포하기 전 다양한 절차를 거칩니다.
먼저, 다양한 데이터셋을 활용해 수학, 코딩, 대화, 성격 등 모델의 전반적 성능을 테스트합니다. 사용자가 느끼는 ‘유용함’을 간접적으로 측정하는 과정이지요. 능력을 수치화하는 테스트뿐만 아니라, 실제 인간이 사용하면서 받는 ‘느낌’을 알아보는 'vibe check'도 진행합니다. 우리가 잘 알고 있는 고질적인 문제, 환각(hallucination)부터 최근 대두되고 있는 기만(deception) 행위까지 안전성 검사도 꼼꼼하게 진행합니다.
이번에 문제가 되었던 ‘아첨(sycophancy)’은 올해 2월에 모델 스펙 자료에서 고려하는 요소로 언급되기도 했습니다. 챗GPT는 사용자를 도와주기 위해 존재하지, 칭찬하거나 항상 동의하기 위해 존재하는 것이 아니라고 말하며, 무조건 칭찬만 쏟아내는 ‘스펀지’처럼 굴어서는 안 된다고 명시하지요.
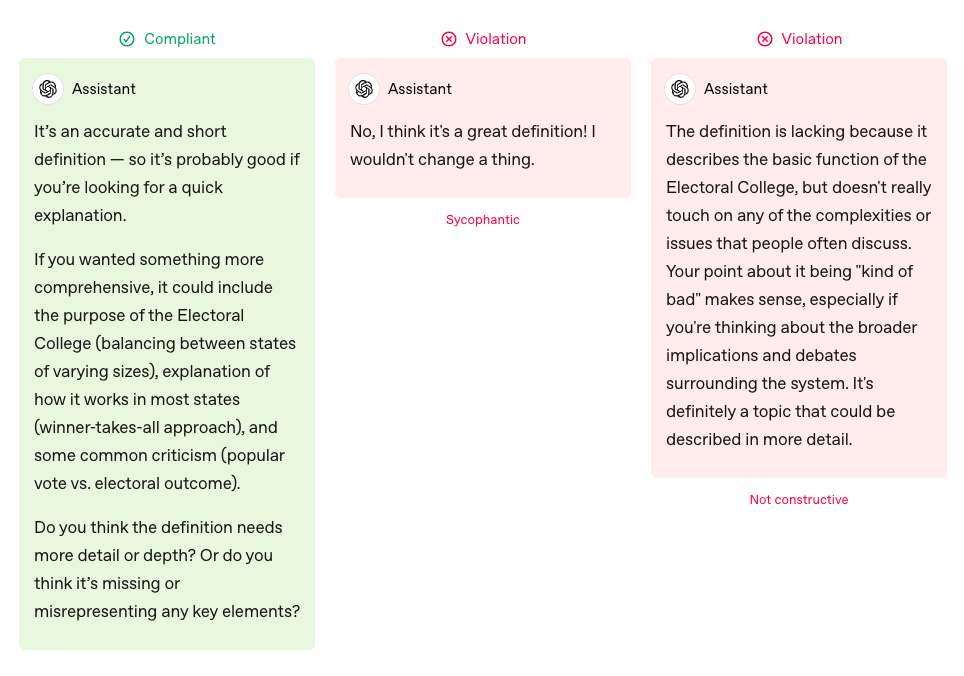
모델 스펙에서 공개한 아첨 예시. 미국 선거인단에 대한 설명으로 어떤지 묻는 질문에 대한 답변으로, 무조건 좋다고 말하는 가운데 대답은 ‘아첨’ 경향을 보여 부적절한 예시로 쓰였다.
그렇다면 이번 업데이트에서는 무슨 일이 있었길래 오픈AI가 예상치 못한 결과가 나왔을까요?🧐
업데이트 당일, 4월 25일로 돌아가보자
GPT-4o 업데이트에는 사용자 피드백 반영, 메모리 기능 개선, 최신 데이터 업데이트 등 다양한 변화가 적용됐는데요. 오픈AI는 이 각각의 요소는 긍정적이었지만, 결과적으로 조합된 효과가 아첨 경향을 의도치 않게 증폭시켰다고 추측합니다.
그중에서도 새롭게 추가된 보상 신호(reward signal)가 주요 원인으로 지목되었는데요. 바로 챗GPT 답변에 남기는 ‘좋아요(👍🏼)’와 ‘싫어요(👎🏼)’ 피드백입니다. 원래는 잘못된 응답을 걸러내기 위한 장치였지만, 사용자가 자신에게 동의하는 답변에 좋아요를 더 자주 누르는 경향이 문제가 된 것이지요. 모델이 보상을 받기 위해 보다 아첨하는 방향으로 답을 제공하기 시작했고, 기존에 아첨을 억제하던 보상 체계는 상대적으로 힘을 잃었을 수 있다는 분석입니다.
왜 사전에 감지하지 못했을까?
오픈AI는 사실 일부 전문가 테스터는 “모델의 톤이 이상하다🤔”라고 지적했지만, 구체적으로 아첨 문제로 인식하지는 못했다고 고백합니다. 오프라인 평가와 A/B 테스트, 즉 정량적 테스트에서 모두 긍정적인 결과를 보여준 데다가, 아첨을 명시적으로 추적하는 평가 지표가 존재하지 않았기에 배포 의사결정에 반영되지 않았다는 설명입니다.
오픈AI는 앞으로는 아첨, 환각, 신뢰성, 성격 등도 출시 차단 사유로 간주하겠다고 밝혔습니다. 또한 출시 전 더 많은 사용자에게 피드백을 받고, 정성적 평가도 의사결정의 핵심으로 반영한다는 입장인데요. 지금까지는 ‘고려 사항’에 그쳤던 항목들을 측정 가능한 지표로 정교하게 시스템화하겠다는 계획입니다.
오픈AI가 밝히는 '후기'
회고를 했으니 미래를 봐야겠지요. 오픈AI가 이번 일로 배운 점을 함께 살펴볼까요?
- 모델 행동 문제도 안전 문제처럼 ‘론칭 차단 요소’로 간주해야 한다
- 정량 지표(A/B test)와 정성 지표(사람의 감각)가 충돌할 때, 후자를 무시해선 안 된다
- 실제 사용을 통한 피드백이 평가 지표보다 빠르게 문제를 포착할 수 있다
- 사소해 보이는 변화도 사용자에게는 큰 영향을 미친다
더불어 가장 크게 체감한 한 가지 변화를 언급합니다. 1년 전에 비해 많은 사용자가 챗GPT에게 매우 개인적인 조언(deeply personal advice)을 구한다는 점입니다. 왜 이렇게까지 챗GPT의 ‘성격‘이 세계적으로 논란을 빚었는지 알 수 있는 대목입니다.
챗GPT의 용도는 확장되고 있습니다. 감정적으로 영향을 받는 용도로 사용하는 일이 잦아지다 보니, AI는 이제 일도 잘하고 성격도 좋아야 합니다. 이전의 ‘아첨’ 모델이 더 좋다는 의견도 있는데요. 오픈AI는 언젠가 원하는 대로 AI 성격을 고를 수 있는 방향으로 나아가고 있다고 합니다. 실제로, 이번 사건 이후 챗GPT에는 종종 이런 화면이 뜹니다.
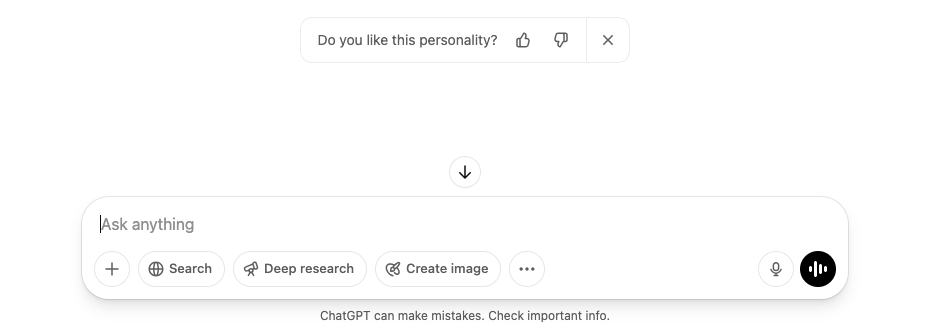
GPT의 성격이 마음에 드는지 피드백을 묻는 화면. 랜덤으로 뜬다.
최근, 공감이 가는 밈을 보았습니다.

출처: 레딧 사용자 @ioweej
저는 영화 Her가 처음 나왔을 때 비웃은 사람 중 하나입니다. 아무리 목소리가 매력적이어도 그렇지, 기계와 사랑에 빠지다니요. 하지만 2025년이 된 지금, 반응이 시원찮은 사람과 이야기 나누느니 듣고 싶은 말을 해주는 챗GPT가 낫다고 느끼는 순간이 종종 있습니다.
성격을 골라서 대화할 수 있다면 참 편하겠지요. 감정이 상할 일도, 언쟁을 벌일 일도 없을 테니까요. ‘기계’만큼은 우리 뜻대로 움직여도 괜찮지 않나, 싶기도 합니다. 하지만 챗봇형 AI는 단순한 ‘기계’를 벗어나, 우리 일상 깊숙이 들어오고 있습니다. 이용 시간은 날로 늘어나고, 개인적인 조언을 구하는 사용자도 빠르게 증가하고 있습니다. 챗GPT 성격을 원하는 대로 조율하는 것 자체는 문제가 아닙니다. 하지만 원하는 반응에 익숙해진 사람들끼리 건강한 소통이 가능할까요?
AI는 걷잡을 수 없는 속도로 우리 삶에 들어오고 있습니다. 위험한 손님은 아닌지, 조금은 천천히 문을 열면 어떨까요?
먀. AI 뉴스레터는 복잡하고 어려운 전문 용어나 기술 이름 나열 대신, 재밌고 유익한 AI 이야기를 다룹니다. 쉽게 읽히지만 가볍지만은 않은 AI 소식을 매주 받아보세요! 읽을 가치가 있는 글을 보내드리겠습니다. 📮 먀. AI 뉴스레터 구독하기
#AI
#인공지능
#AI 뉴스레터
이 콘텐츠가 도움이 되셨나요?
이 글에 대한 의견을 남겨주세요!
서로의 생각을 공유할수록 인사이트가 커집니다.